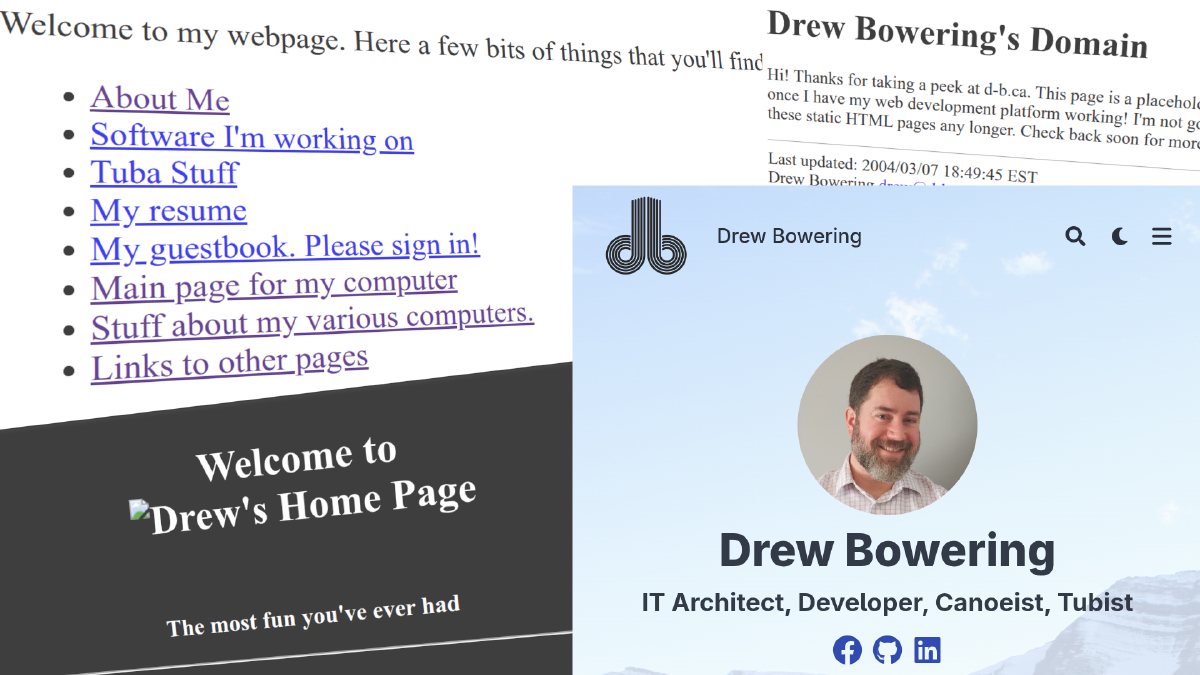

I’ve finally published a proper website at https://d-b.ca/. The last time I had anything live on this domain was over 20 years ago, according to the Wayback Machine. What took so long? The truth is, my interests have shifted over the years, and I’ve been learning a lot. This site, while useful in its own right, is really a culmination of a personal platform I’ve developed over time.
History#
My first personal website was developed while I was a student at the University of Alberta, near the end of the previous century. The web was still in its early stages, but the university provided students with the means to publish web content. It was mostly a novelty at the time and didn’t last beyond my time at school, but it sparked my interest in Internet technologies and their applications.
That early site included one interesting feature. I developed a mechanism to automatically update a page every time I logged into one of the school’s computers, so my friends could find me if they wanted to. At the time, dynamically updating websites was a tricky thing. The most common way was using CGI, which is like having a tiny program run every time someone requested a page. The university did not allow student sites to use it. So, I wrote some shell scripts that were called as part of my login and logout scripts that would generate the static HTML file and write it to my web content directory. It needed to handle cases like multiple logins, and the logout script didn’t always get triggered, so I’d have to keep an eye on it for stale entries.
Self-Hosting#
I’ve always been an avid self-hoster. Learning by getting a system up and running works well for me. I also value the privacy and control that it provides. Plus, it’s much cheaper for me in the long run!
It really began when I was working at a local Internet service provider. I was
able to get a special deal on a good broadband connection at home, which
included a small network block (a /28, consisting of 16 IP addresses) that I
could use. I dedicated my largest machine as my server and developed several
services, including a new website.
My website at that time wasn’t fancy, and was geared primarily towards experimentation. I developed a simple content management system from scratch in PHP, which I used to publish a blog. It also integrated with mailing lists, another area I was exploring at the time.
D-B.CA#
I hadn’t registered a domain name of my own in those early days, so everything
resided under a friend’s domain. In late 2002, I decided to finally register
one of my own, primarily so I could have a stable email address. I wanted to
incorporate the initials in my name, so I came up with d-b.ca. This was a
compromise because someone was squatting on db.ca at the time, and, to my
knowledge, they still are.
Early on, I focused mostly on operating my email services and other experiments, with little attention paid to a website. There were a few test pages at times, but nothing substantial.
Modern Technology#
One of the projects I’ve been following is Hugo. I’ve seen and worked with various web content management systems in the past, and they often feel cumbersome and present security concerns. Hugo is an example of a “Static Site Generator.” Think of it like this: instead of creating web pages on the fly every time someone visits, Hugo takes all the raw content and turns it into a set of ready-to-serve files, much like a compiler turns code into an executable program. The resulting static resources can be served as regular files from any web service, without the need for dynamically generating content upon request from a database, as traditional CMS systems do.
Using Hugo is much easier with a solid base template. There are many to choose from, including the one I’ve selected here called “Blowfish”. I like how it looks, and it supports the style of site that this is very well.
Another benefit of a static site generator is that all the sources for the site can be treated like software code, making it simple to use development tools like Git for version control. I keep the sources for this site in a public repository on my own Git server. Feel free to take a look:
CI/CD#
I’ve also set up a CI/CD pipeline to build and deploy the site whenever changes are made to the source repository. What does this mean?
CI = Continuous Integration
This is the practice of frequently integrating changes into a source repository. The changes are checked, assembled, and packaged through automated processes. More information
CD = Continuous Delivery
This is the capability of being able to take new changes (such as the outputs of the CI process) and getting them deployed and running automatically. More information
The CI portion is triggered by a push to the
web repository. It runs an automated
workflow that builds the site and packages the resulting artifacts into a
container image based on the Caddy web server.
A container image is like a pre-packaged software environment that ensures the website runs consistently regardless of the underlying infrastructure. The resulting image contains everything the website needs to operate and can run on any infrastructure that can support it, such as my own laptop or my server cluster.
The build container with Hugo is another image that is only used to create the website container. I maintain it in this repository:
After the workflow has built the container image for running the website, it updates the CD GitOps repository to deploy this new version immediately to a private staging site. Another definition:
GitOps refers to the practice of managing infrastructure automation by keeping machine-readable descriptions of the intended infrastructure in a version-controlled Git repository. A CD system will monitor the repository for changes, immediately adding, modifying, or removing infrastructure to bring the state of the operational system into alignment with the source description.
There are many benefits to managing infrastructure this way. Changes are automatically tracked because everything is stored in an existing code repository system that’s specifically designed for managing and tracking change. Problematic changes can be reverted easily by reverting the change in the repository. Automation keeps things in sync at all times - any changes made manually outside of this system are immediately spotted and removed.
When I want to publish the new version as the production website, I use my regular private production GitOps repository to update the image version tag, and the rest happens automatically. The CD repository for the staging site is public, you’re welcome to check it out here:
Pipeline Diagram#
flowchart TB
subgraph GIT [Git Repository]
WR[(Web)]
CDR[(CD)]
end
WP(Push Web Updates)-->WR
WP ~~~ HBI
subgraph CI [CI Workflow]
CIP[Pull Source
Repository]-->BWI[Build Web
Image]
BWI-->PWI[Push Web
Image]
PWI-->UCD[Update CD
Repository]
end
PWI-->WI
WR-->CIP
subgraph DOCKER [Image Repository]
HBI((Hugo
Build))
WI((Web))
end
HBI-->BWI
UCD-->CDP(Push Image
Update)
CDP-->CDR
CDR-->CDPull
subgraph CD [CD Process]
CDPull[Pull Source Repository]-->DWI[Deploy Web Image]
end
WI-->DWI
Underlying Platform#
In future articles, I’ll describe the evolution of the physical network and systems this site is running on, and how they enabled me to build a Kubernetes cluster to scale this site and run other services, all on hardware I assembled myself!